- SS&C Blue Prism Community
- Get Help
- Digital Exchange
- Dynamic File Path
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Dynamic File Path
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
24-02-20 12:48 PM
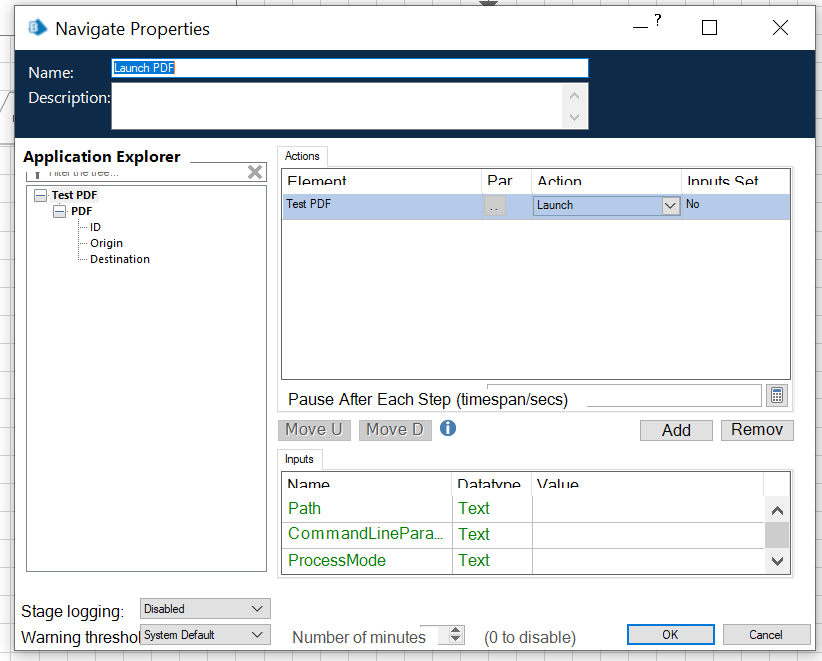
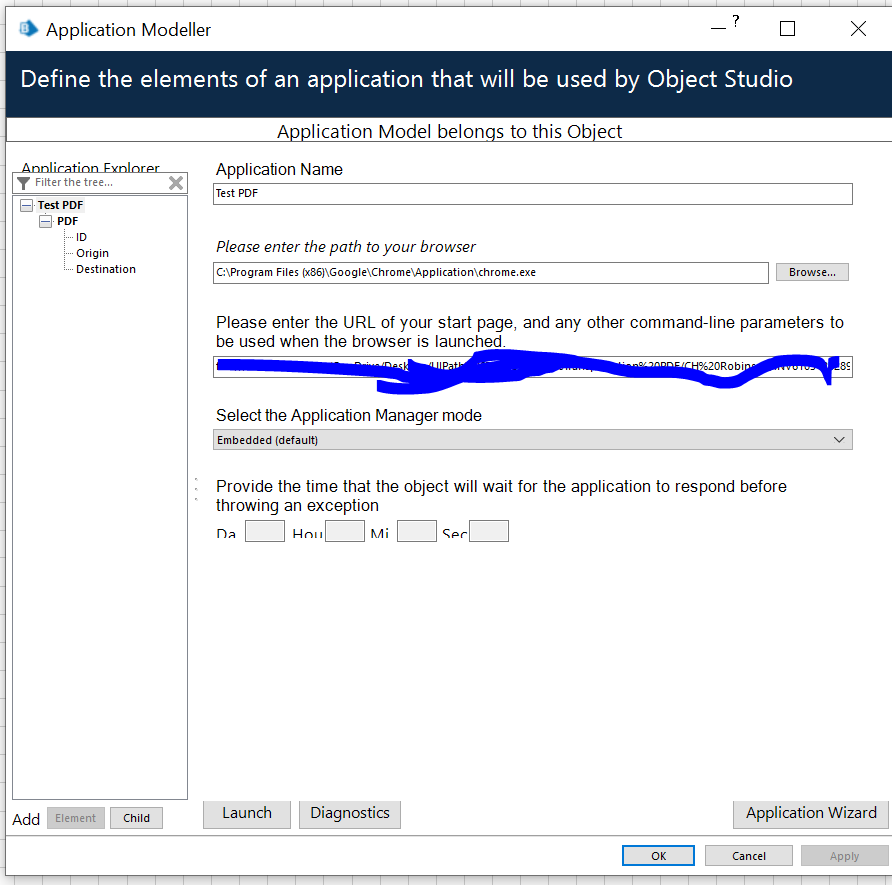
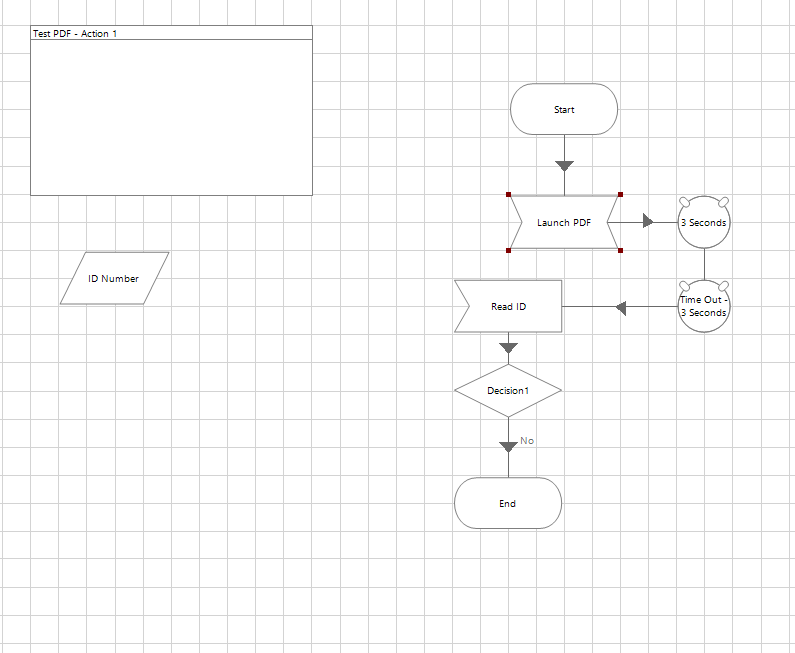
I'm trying to build a machine that points to a pdf in a template format and scans information for some minor analysis. I've built out an object that scrapes the pdf correctly for the information that I want. My issue is that to do that I'm using the Application Manager to open the PDF and scrape, but I have to point the Application Manager to a SPECIFIC PDF, meaning that I can't change the file;path form PDF1 to PDF2 in my object.
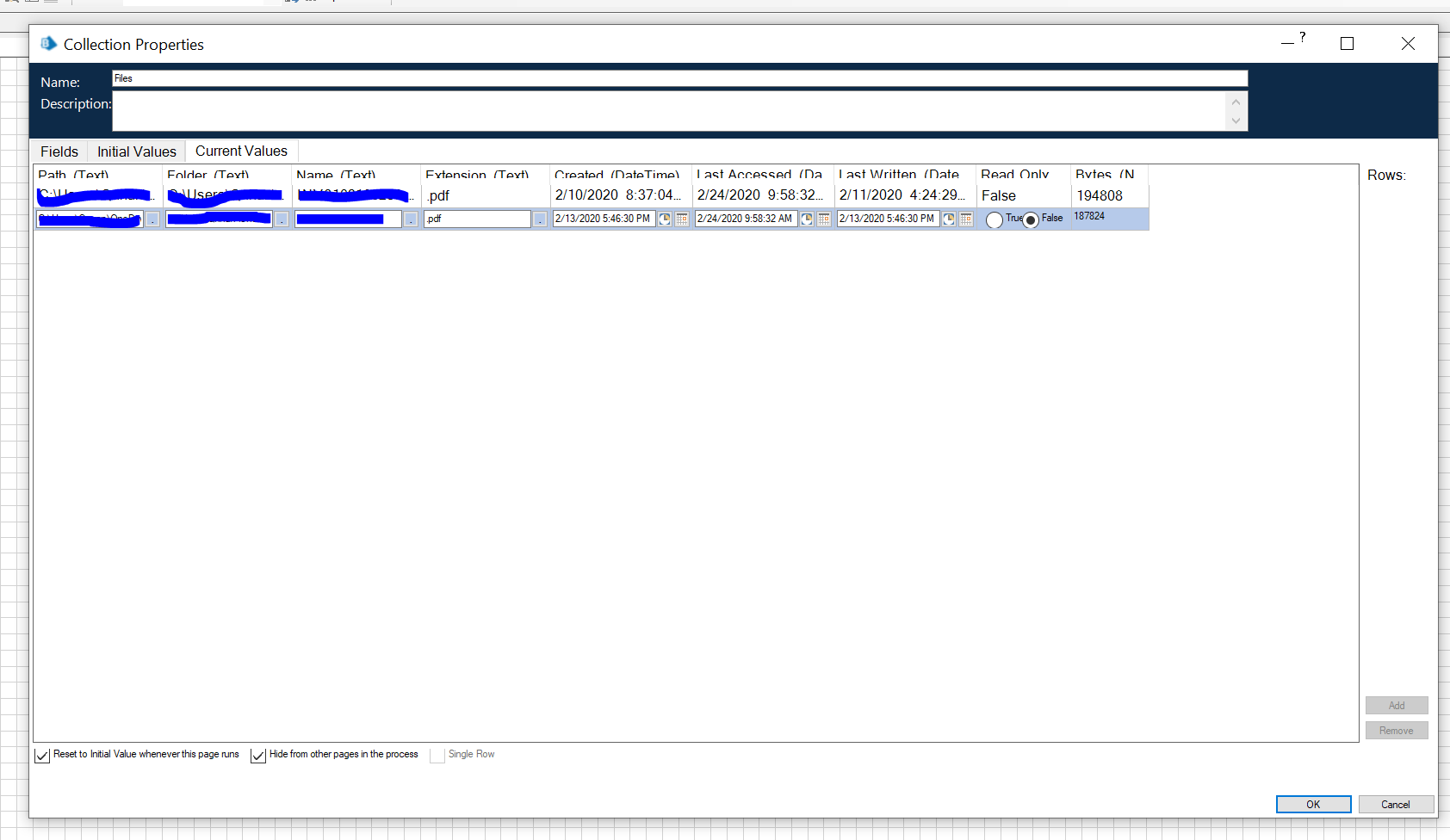
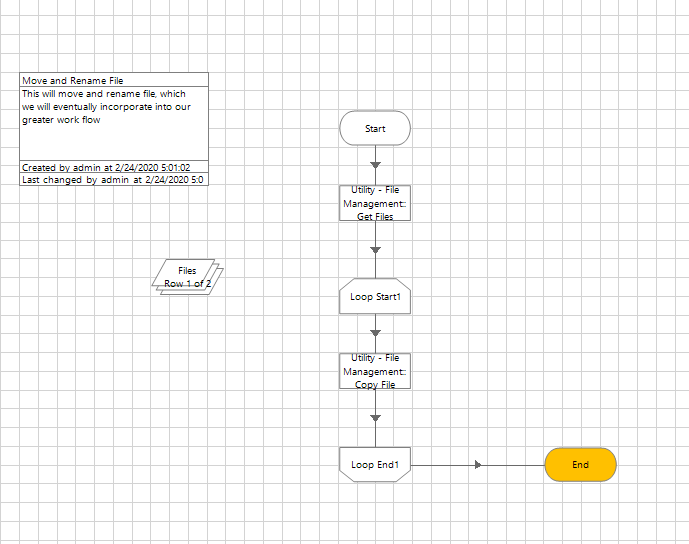
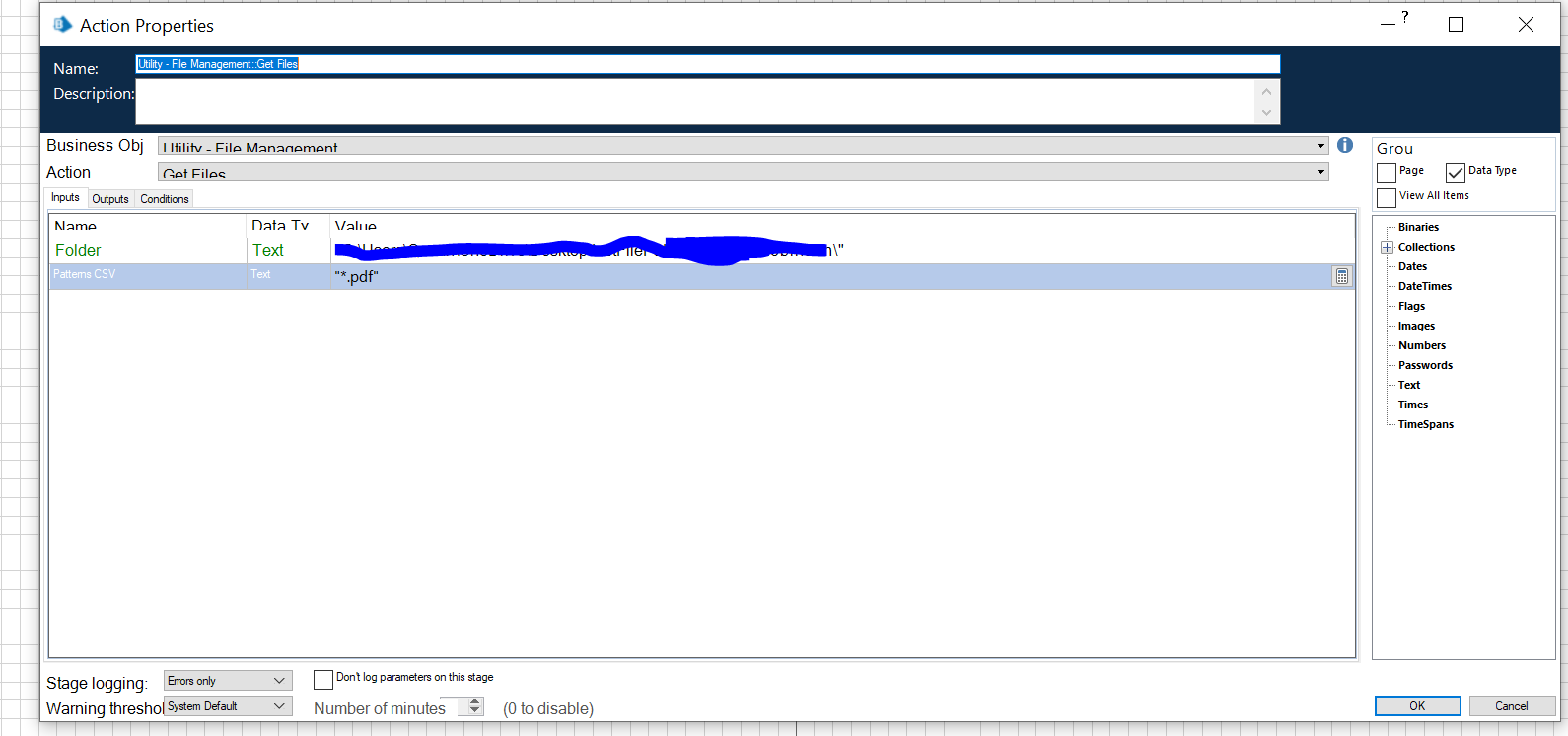
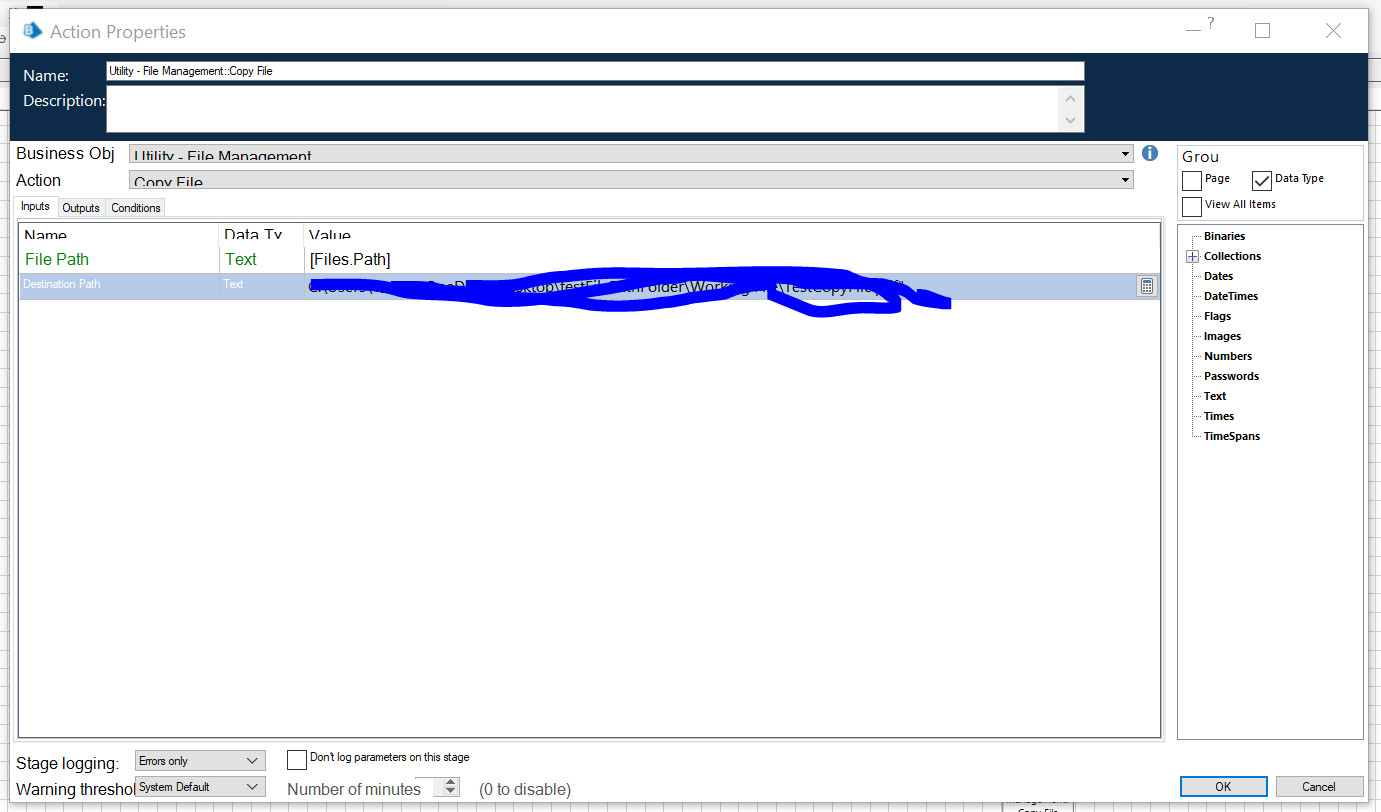
I tried to get around this by building an system that grabs all the filepaths in a folder (the Get Files action in the System Management VBO), then loops through an action that copies the files into a single 'master file' (using the Copy Files action in the System Management VBO) that would then be used to perform the PDF Scraping action. Only, for some reason I can't call the full PDF filepath from the Collection the Get Files action builds. Meaning the loop is calling on the whole collection I'm creating and won't pass individual values into the Copy File action. The Collection is populating with the Get Files action, but isn't allowing me to pull individual fields from the collection.
Help with either directly solving the dynamic filepath for the PDF or solving this looping issue would be greatly appreciated.
------------------------------
Quinn Anderson
------------------------------

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
24-02-20 02:15 PM
For example, your first paragraph leads me to believe you're putting the path to the file inside of Application Modeller, but you should actually pass it to a navigate stage used to Launch. Or (and probably better since Adobe can get disconnected from BP) use the action 'Start Process' in the 'Utility - Environment' VBO and then use a navigate stage to attach to Adobe once its opened using the window title and process name.
As far the looping, how are you referencing the field in the collection? If I remember right, the Get Files action outputs a collection that has a field name called something like Path. You'd be doing like [CollectionName.Path] in the input to Copy File.
The last thing I'm wondering about is whether you have considered other ways to get data out of a PDF. There are several ways to extract text from PDFs without opening the PDF on the screen. If you're interested in that, I can mention the few ways I'm aware of. Also I'm just assuming you're opening in Adobe, so I may be way off on the suggestion.
------------------------------
Dave Morris
3Ci @ Southern Company
Atlanta, GA
------------------------------
Dave Morris, 3Ci at Southern Company
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
24-02-20 03:00 PM
I'm currently using the scanning method because it's the best way I'm aware of BluePrism being able to do the work. I would love other methods if you could provide them! 🙂
------------------------------
Quinn Anderson
------------------------------
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
25-02-20 12:41 PM
I'm assuming you're using the navigate action 'Recognize Text'. I forget what it's called at the moment, but I'm referring to the one that uses the Google Tesseract OCR engine that comes with Blue Prism now. So, what you can do is actually still use that same engine and even use the same thing Blue Prism is using to read the text off the PDF, but you can do it without ever opening Adobe and without dealing with any UI.
I've only half proofed this out (the 2nd half below), but I have confirmed this should all work fairly reliably. I cannot attach screenshots from where I am, so I'll just be using text unfortunately.
You need two components/parts/pieces: (1) a code stage to convert your PDF to an image type like .PNG or .TIF AND (2) use the command line commands to call the Tesseract exe in the Blue Prism Automate\Tesseract folder.
For (1), I haven't done this part yet, but it really looks as simple as downloading a DLL or two and copy/pasting some code into a c# code stage. Try here: https://stackoverflow.com/questions/23905169/how-to-convert-pdf-files-to-image. If I end up proofing this out as well, I'll try to remember to come back and update this post or reply again.
For (2), I imagine you could use the 'Utility - Environment' VBO for one of its actions that runs processes in order to run the Tesseract exe. I did have luck with it 'working', but Blue Prism is receiving standard error output text that shouldn't be error output. Anyway, you may see this when you try it. First though, try from command line.
This command: C:\Program Files\Blue Prism Limited\Blue Prism Automate\Tesseract\tesseract-4.0.0 C:\Temp\test.tif C:\Temp\out
Replace the first path 'C:\Temp\test.tif' with wherever your input file is and the second path 'C:\Temp\out' with where you want the output to go. Don't put a .txt extension on the output location because Tesseract will do that.
Two things to note:
- Supposedly TIF is the best file type to use for this, though PNG/JPG etc. may also work.
- From my minimal research and testing, the image has to be exactly 300 DPI. Converters typically will ask you what DPI you want especially for converting to TIF files.
The text output will go into the output text file, and then you can read that into Blue Prism and do string manipulation on it.
------------------------------
Dave Morris
3Ci @ Southern Company
Atlanta, GA
------------------------------
Dave Morris, 3Ci at Southern Company
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
25-02-20 10:40 PM
I can try running a different PDF recognition method, but to be honest I'm running on a deadline and would like this to be resolved sooner than later. I'm also concerned with BluePrism's relatively lack of string comprehension flexibility. It doesn't seem to be able to parse words versus characters, and the PDF's change word and character location because items like Addresses change the numeric location of the material I want to parse. I'd rather just point to a PDF and get it to pull out the material I need.
------------------------------
Quinn Anderson
------------------------------
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
26-02-20 11:59 AM
I can certainly understand a deadline keeping you on the track you already started on. You may want to spend a bit of time here and there trying a non-UI method so that it could be used in a future iteration of your automation. There are other ways as well such as API calls to a service like Amazon Textract too. By far, in my opinion, the way I suggested above is the easiest and quickest to implement.
------------------------------
Dave Morris
3Ci @ Southern Company
Atlanta, GA
------------------------------
Dave Morris, 3Ci at Southern Company
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
26-02-20 12:30 PM
I definitely respect that I should take the time to learn a more effective method for working with PDF's moving forward, but I would still like to be able to do it this way as I feel like my lack of understanding of the tool is the major hurdle for the current implementation.
------------------------------
Quinn Anderson
------------------------------
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
26-02-20 12:34 PM
You'll want to change it to coordinates inside the editor for Region Mode. Choose the element and then change Image to Coordinates. I think it's called 'Location Method' or something like that. Anyway, if it's set to Image, then it definitely will never work for anything but the original PDF and only if the text looks exactly the same because it's finding the region based on the way the image looks. If it cannot find the exact same image, then it will never locate it. If I remember right, the Coordinates should be in relation to the top left of the app rather than the top left of the window. Probably want to verify that, but I think that's how it is. Then just make sure your region is big enough (maybe the size of the entire app if you want).
Note that I found if you have the zoom level too low then the OCR has a hard time reading the text. But, if it works for you while showing the full page, then I'd do the same.
------------------------------
Dave Morris
3Ci @ Southern Company
Atlanta, GA
------------------------------
Dave Morris, 3Ci at Southern Company
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
26-02-20 02:05 PM
------------------------------
Quinn Anderson
------------------------------
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Email to a Friend
- Report Inappropriate Content
26-02-20 02:13 PM
------------------------------
Dave Morris
3Ci @ Southern Company
Atlanta, GA
------------------------------
Dave Morris, 3Ci at Southern Company
